Kto się boi, a kto czuje odrazę - analiza tweetów polskich partii politycznych
Czy język polskiej polityki ocieka (negatywnymi) emocjami? A może to tylko złudzenie, któremu ulegamy? Dzisiaj szychta analizuje tweety 5 partii politycznych i sprawdza jak mocny ładunek emocjonalny w sobie zawierają.
Poniższy wykres należy rozumieć w następujący sposób. Każda z 5 osi opisuje jedną emocję. Punkty na osi odpowiadają poszczególnym partiom politycznym. Kolejne emocje połączone są liniami, aby łatwiej było śledzić różnice między ugrupowaniami. Linie poprzeczne odpowiadają skali emocji. Im bliżej środka tym emocje są mniejsze. Przykładowo, w tweetach Kukuz15 poziom strachu jest najwyższy. Nieco niższy cechuje Nowoczesną, PO i Razem. Najniższy obecny jest w tweetach PiSu.
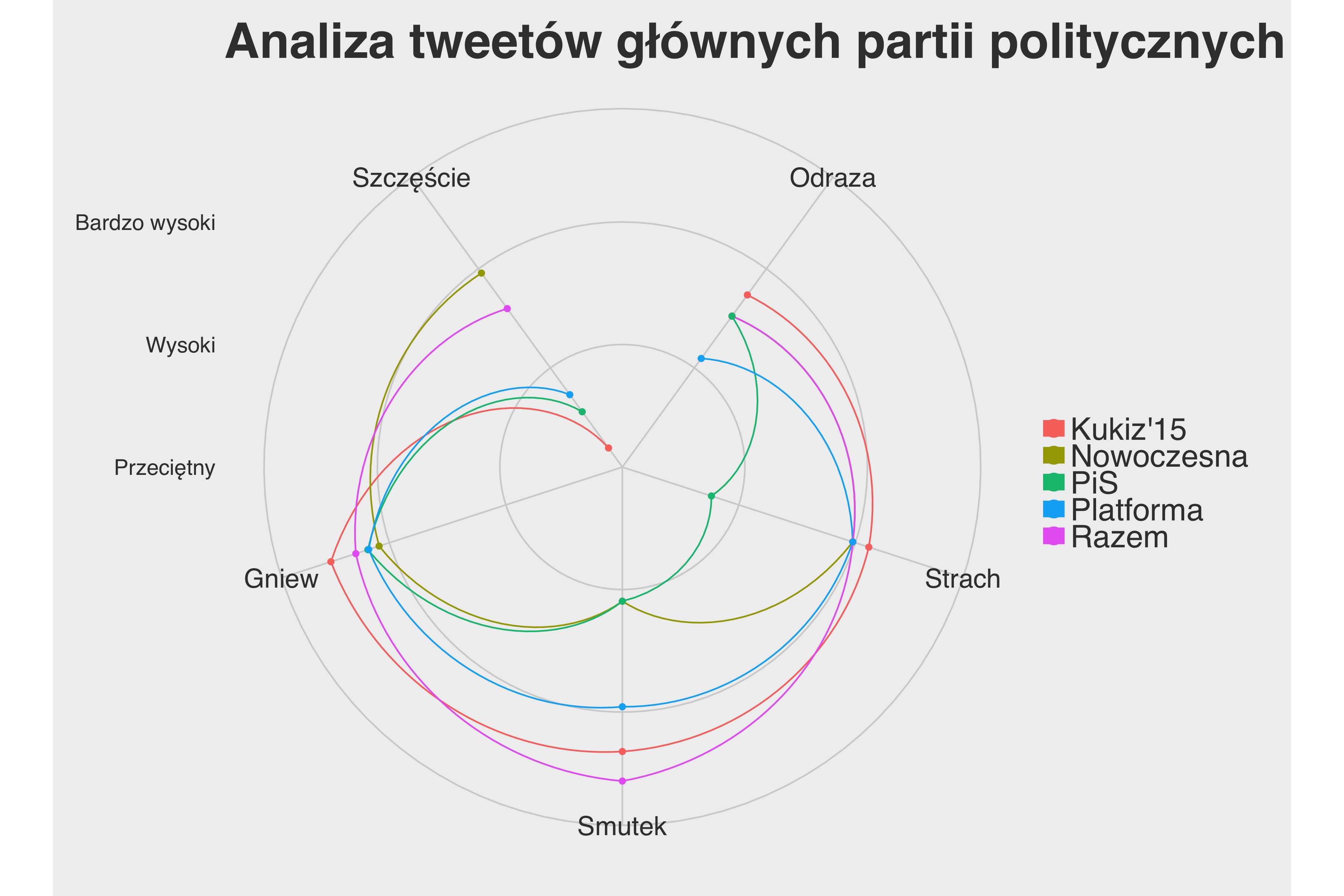
Cześć zależności jest oczekiwana. PiS jako partia władzy nie emanuje strachem. Odwrotnie u partii opozycyjnych, które mówią o zagrożeniach ze strony działań rządu. Najwięcej emocji negatywnych mają Kukiz15 i Razem - dwa ugrupowania, które są w kontrze do istniejącego establishmentu. Ciekawe są wyniki dla radości. Najczęściej dzieją się nią ze swoimi ,,śledzącymi" Nowoczesna i Razem. Poziom gniewu jest dosyć podobny u wszystkich partii. Co ciekawe, z analizy wynika, że partie używają języka nacechowanego emocjonalnie. Średnie emocje w każdej z kategorii, dla wszystkich partii są wyższe, niż przeciętne emocje jakie wywołują słowa (bierzemy pod uwagę 2900 słów). Więcej szczegółów dotyczących metodologii można znaleźć poniżej.
Metodologia
Pobrałem 1000 ostatnich tweetów każdej z 5 partii. Brałem pod uwagę zarówno treści stworzone przez dane profile, jak i retweety. Tekst z tweetów przetworzyłem za pomocą taggera WCRFT2. Dla każdego słowa wziąłem pierwsze dopasowanie zwrócone przez tagger. Następnie słowa połączyłem z Nencki Affective Word List (NAVL), bazą zawierającą 2902 słowa, wraz z ich ładunkiem emocjonalnym pod kątem szczęścia (radości), gniewu, smutku, strachu i odrazy. Po połączeniu ,,tagów" z bazą navl otrzymałem dla każdej z partii około 200 słów. Oczywiście wiele z nich występowało w tweetach wielokrotnie. Dla każdej z partii policzyłem średnią ważoną poziomu emocji używanych słów. Następnie odniosłem otrzymane wyniki do odpowiadającego im kwantyla wśród wszystkich słów w bazie navl. Poziom przeciętny na wykresie odpowiada 55 centylowi, wysoki 60 centylowi, bardzo wysoki 65 centylowi. Użycie tych nazw jest usprawiedliwione, ponieważ mamy do czynienia ze średnimi wartościami ze sporej długości tekstów.
Kody zostaną udostępnione na githubie (po wyczyszczeniu, które może zająć kilka dni).
Podziękowania dla Adama Radziszewskiego, dzięki któremu dotarłem do narzędzi służących do automatycznego przetwarzania języka polskiego.